I joined Grovio at a critical moment.
The startup had thousands of AWS credits from the promotional free tier, but they were hemorrhaging money—$1500 a month—on infrastructure that looked more like a garage experiment than a foundation for a company.
They had 10+ EC2 instances of varying sizes (m5.large to t2.xlarge), running multiple containerized services, each managed manually through the AWS console. There were no documents. No infrastructure-as-code. Just a lot of hopeful clicking around and crossing fingers.
At that burn rate, the company would exhaust its runway before launching.
The problem wasn’t the cloud. The problem was the infrastructure was being “vibe coded” — and nobody realizes how expensive that is until it’s too late.
The Chaos of Vibe Coding Infrastructure
Let me be direct: clicking around the AWS console without infrastructure documentation is the startup equivalent of building a house on sand.
Here’s what was happening at Grovio:
- No version control for infrastructure: Changes were made in the console, noted nowhere, and lost when someone left
- New team members = chaos: When someone new joined, nobody could explain why certain instances existed or what they were running
- Manual scaling = throwing money at problems: When load increased, the answer was “add another instance” rather than optimizing what existed
- Impossible to debug: Something broke? Good luck figuring out what changed and when
- Team confusion: Everyone had their own mental model of what was actually running in production
I’ve seen this pattern a hundred times. Junior engineers, startups under pressure, founders wearing too many hats—they all fall into the same trap: treating infrastructure like it’s temporary, when it’s actually foundational.
The cost? It compounds. Every manual decision made in the console is a technical debt that your future self has to pay interest on.
The Turning Point: Infrastructure as Code
I could have suggested Kubernetes. It’s powerful, scalable, and would definitely handle Grovio’s current and future needs.
But here’s the thing: Kubernetes is a solution to a problem Grovio didn’t have yet.
What Grovio needed was:
- Clarity (version control, not chaos)
- Cost efficiency (stop paying for idle resources)
- Team velocity (faster, repeatable deployments)
- Simplicity (no PhD in infrastructure required)
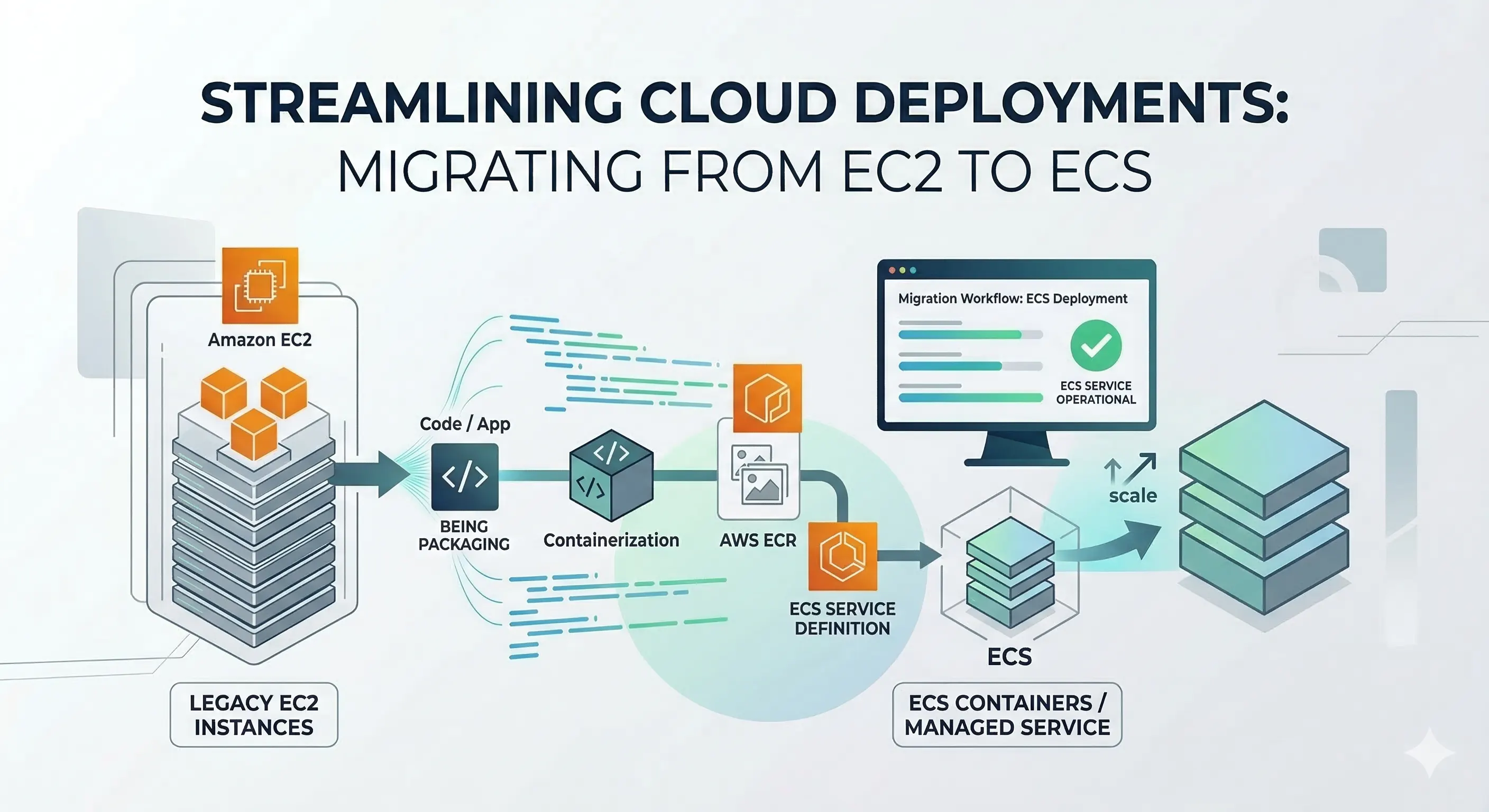
So I chose AWS CDK + ECS migration + monorepository consolidation.
Not because it’s the most sophisticated solution. But because it’s the most pragmatic one.
What we did
- Migrated from EC2 to ECS – consolidate all those scattered instances into managed container services
- Unified the repositories – one frontend repo, one backend/agent repo instead of scattered codebases
- Wrote the infrastructure in CDK – defined everything as code (in TypeScript), version controlled it, and deployed it repeatably
The beauty of this approach? The infrastructure became as maintainable as the code itself.
The Results
Here are the numbers that matter:
| Metric | Before | After | Change |
|---|---|---|---|
| Monthly Cost | $1500 | $200 | 86.7% reduction |
| Deployment Time | 4+ hours | ~10 minutes | 98% faster |
| Infrastructure Documentation | Manual notes (outdated) | Code itself (always current) | ✅ Solved |
| Team Onboarding | ”Someone explain this" | "Read the CDK code” | ✅ Self-service |
The cost reduction alone saved the startup’s runway. But the real win was the deployment velocity—going from half-day deployments to 10-minute cycles meant the team could iterate, test, and ship without waiting around.
A Quick Look at AWS CDK
CDK is infrastructure-as-code using actual programming languages (TypeScript, Python, Go, etc.). Instead of clicking around the console, you write code that defines your infrastructure.
Here’s a simplified example of what an ECS setup looks like in CDK:
import * as cdk from 'aws-cdk-lib';
import * as ecs from 'aws-cdk-lib/aws-ecs';
import * as ec2 from 'aws-cdk-lib/aws-ec2';
export class GrovioStack extends cdk.Stack {
constructor(scope: cdk.App, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const vpc = new ec2.Vpc(this, 'GrovioVpc', {
maxAzs: 2
});
const cluster = new ecs.Cluster(this, 'GrovioCluster', {
vpc: vpc
});
// That's it. Your cluster is defined, version controlled, and reproducible.
}
}This isn’t magical, but it is powerful: your infrastructure is now code. You can:
- Version control it (git history shows every change)
- Code review it (infrastructure changes go through pull requests)
- Test it (before deploying to production)
- Reproduce it (spin up new environments identically)
Compare that to the alternative: clicking around the AWS console, trying to remember what you clicked last time, and hoping the next person can figure it out.
The IaC Advantage: Flexibility Meets Caution
Here’s where IaC gets interesting: because your infrastructure is now code, you can iterate on it fast.
You can use Claude, ChatGPT, or any AI tool to help you optimize your infrastructure definition. Want to add caching? Generate it. Need to scale horizontally? AI can help. Want to add observability? Done.
The flexibility is incredible. But here’s the catch: flexibility without discipline is expensive.
I’ve seen teams use AI to generate infrastructure improvements without fully understanding what was added. A line here, an extra resource there, some optimization you didn’t question—and suddenly your monthly bill jumped $300 without explanation.
The danger isn’t IaC. The danger is unknown delta: changes made to infrastructure (whether by AI, by you, or by a teammate) that you didn’t fully review or understand, which cascade into unexpected costs.
Here’s how to avoid it:
- Understand what you’re adding – if you copy-paste CDK code from Claude, read it. Understand every line. Does it add a NAT gateway? Does it provision more instances than before? Know the cost implications.
- Review infrastructure changes like code – pull requests for infrastructure changes should be as rigorous as code reviews. “Why did we add this resource?” should be answerable in the PR description.
- Monitor your actual spend – version control + cost monitoring go hand-in-hand. Set up billing alerts. Track what’s actually running versus what the code says should be running.
- Keep it simple – the best infrastructure is the infrastructure you understand. Don’t over-engineer “just in case.” That hypothetical scale problem you’re trying to solve? Probably won’t happen. The guaranteed cost problem? Will.
IaC makes it easy to make infrastructure changes. That’s both a superpower and a trap. Use it wisely.
Why Not Kubernetes?
I know what some of you are thinking: “Why not go straight to Kubernetes? It’s more scalable, more flexible, way cooler.”
You’re right on all counts. But here’s the honest truth: Kubernetes is powerful for problems Grovio didn’t have.
Kubernetes adds complexity:
- More infrastructure overhead
- Steeper learning curve for the team
- More places for things to break
- More operational burden
At that stage, Grovio needed speed and clarity, not infinite scale. ECS with CDK gave them both, immediately.
You can always migrate to Kubernetes later if you need to. But most startups never get there—because by the time they need that scale, they’ve hired engineers who actually know what they’re doing, and the early “vibe coding” mistakes have already been fixed.
The Lesson for Vibe Coders Everywhere
Here’s what I want you to take away:
Infrastructure decisions compound. When you “vibe code” your infrastructure, you’re not just making a temporary choice—you’re creating a debt that costs real money and real time.
The startup I worked with was this close to failing because nobody treated infrastructure as seriously as they treated their codebase. Once we did, everything changed:
- The team moved faster (no waiting for manual deployments)
- The cost became sustainable (86% reduction)
- New people could understand the system (because it was code, not mystery)
- Infrastructure decisions became traceable (version control = accountability)
The Uncomfortable Truth
If you’re a “vibe coder” clicking around your AWS console right now, you are almost certainly burning money you don’t know about.
You might not think it matters in month one. It matters in month six, when you realize you’re paying for idle resources, over-provisioned instances, and technical debt that makes every deployment a mini-adventure.
The good news? It’s fixable. CDK makes it simple to start fresh. Not perfect, not over-engineered—just pragmatic, repeatable, and cost-conscious.
What This Isn’t
This isn’t a pitch for AWS CDK specifically. If you prefer Terraform, Pulumi, or CloudFormation, the principle is the same: treat your infrastructure like code.
This isn’t advice that Kubernetes is bad. For companies at Grovio’s scale now, ECS is the right call. Later, who knows?
This is a wake-up call: if your infrastructure exists only in your head and in the AWS console, you’re building on sand.
A Month In
Just a month after the ECS migration and CDK implementation, the results are already clear. Grovio’s team can now:
- Deploy to staging and production in under 10 minutes (versus half-day manual deployments)
- Spin up new environments without manual work
- Understand exactly what’s running and why (it’s all code)
- See a 86% reduction in monthly infrastructure costs
This isn’t a long-term success story yet. It’s a fresh validation that treating infrastructure as code, from day one, pays immediate dividends.
None of this required hiring a DevOps expert with a decade of Kubernetes experience. It just required treating infrastructure like it matters.
Because it does.
The Bottom Line
Infrastructure-as-Code isn’t just a technical best practice. It’s the difference between a sustainable startup and one that’s slowly hemorrhaging money through vague cloud decisions.
Use AWS CDK (or Terraform, Pulumi, whatever). Version control your infrastructure. Document it through code, not spreadsheets.
Because founders and engineers: your infrastructure isn’t temporary. Treat it accordingly.
Want to discuss infrastructure decisions for your startup?
If you’re facing infrastructure chaos, scaling challenges, or just wondering if you’re burning money on AWS, I’m happy to share what I’ve learned from building and fixing distributed systems.
This story is based on a real experience helping a startup transform from vibe-coded infrastructure to disciplined, scalable systems. The principles apply whether you’re using AWS, GCP, Azure, or any cloud platform.